
In data warehousing, facts and dimensions are standard terms. They inform us about things like the number of resources used for a particular task. They both store the exact measure of resources and details about the resource and task.

What Are Facts in Data Warehousing?
A fact in data warehousing describes quantitative transactional data like measurements, metrics, or the values ready for analysis. These include header numbers, order numbers, ticket numbers, transaction numbers, transaction currency, etc.
The amount sold is a fact measure or a key performance indicator (KPI). You can store this information in fact tables at the lowest level of granularity. Facts form foreign key relationships with different dimension tables. In this scenario, a composite primary key contains each attribute of a primary key. This is considered a foreign key to the dimension table.
Examples of facts include the following:
-
Additive
-
Semi-additive
-
Non-additive
Additive describes the measures we must add to all dimensions.
Semi-additive describes what measures can be added to some dimensions but not with others.
Non-additive describes the storage of basic units of measurement of business processes—for example, phone calls, orders, and sales.
What Are Dimensions in Data Warehousing?
Dimensions are companions to facts and are attributes of facts like the date of a sale. For example, a customer’s dimension attributes usually include their first and last name, gender, birth date, occupation, and so on. A website dimension consists of the website’s name and URL attributes. They describe different objects and are denormalized because of one-to-many relationships.
Examples of dimension include the following:
-
Conformed dimensions
-
Degenerate dimensions
-
Dimension-to-dimension table joins
-
Junk dimensions
-
Outrigger dimensions
-
Role-playing dimensions
-
Shrunken rollup dimensions
-
Step dimensions
-
Swappable dimensions
Conformed dimensions are the facts that it’s related to. You can use this dimension in more than a one-star schema or Datamart. A date dimension is an excellent example of a conformed dimension. Attributes such as the month, week, day, or even year communicate the same information across any number of facts. This approach helps create consistency as we can maintain the same across fact tables. Various tables will use the same table across the fact table to create different reports.
Degenerate dimensions don’t have corresponding dimensions. As it’s derived from a fact table, it doesn’t have its own dimension. We use degenerate dimensions to collect snapshots of a fact table. For example, product IDs come from a product dimension table. However, as the invoice number is a standalone attribute with no attributes associated with it, the invoice number can be critical to keeping track of product quantities.
Dimension-to-dimension table joins can reference other dimensions. You can model these relationships with outrigger dimensions.
Junk dimensions form a collection of random transactional codes, text attributes, or flags. They often don’t logically belong to any specific dimension. Most often, the values of these attributes fall under simple (yes/no (or) true/false) indicators. Depending on the complexity, a fact table may have one or more junk dimensions. Junk dimensions are also created to manage foreign keys made by quickly changing dimensions.
Outrigger dimensions sometimes include a reference to another dimension table. In this scenario, secondary dimensions are outrigger dimensions. It’s essentially a performance improvement feature that helps better optimize data models. For example, we can use an outrigger dimension when a dimension table grows too large in terms of the number of columns. In this scenario, you can break down a large dimension table into smaller manageable chunks based on their relationships and analysis demands.
Role-playing dimensions reference links to a logically distinct role for each dimension. Every single physical dimension helps reference multiple times in a fact table. For example, a fact table usually has foreign keys for the shipping date and delivery date. As the same attributes apply to each foreign key, you can join these tables to the foreign keys.
Shrunken rollup dimensions are essentially subdivisions of columns and rows of a base dimension. These dimensions are great for developing aggregated fact tables. It’s handy when business processes naturally capture data at a higher level of granularity. For example, you can forecast by brand and month instead of an atomic date and product related to sales data.
Step dimensions are sequential processes and typically have a separate row in a fact table for each step in the procedure. In an overall session, it tells us where we can use each specific step.
Swappable dimensions are leveraged when you pair the same fact table with multiple versions of the same dimension. For example, you can simultaneously expose stock ticker quotes to several different investors from a single fact table. This is possible as each has its own unique and proprietary attributes assigned to various stocks.
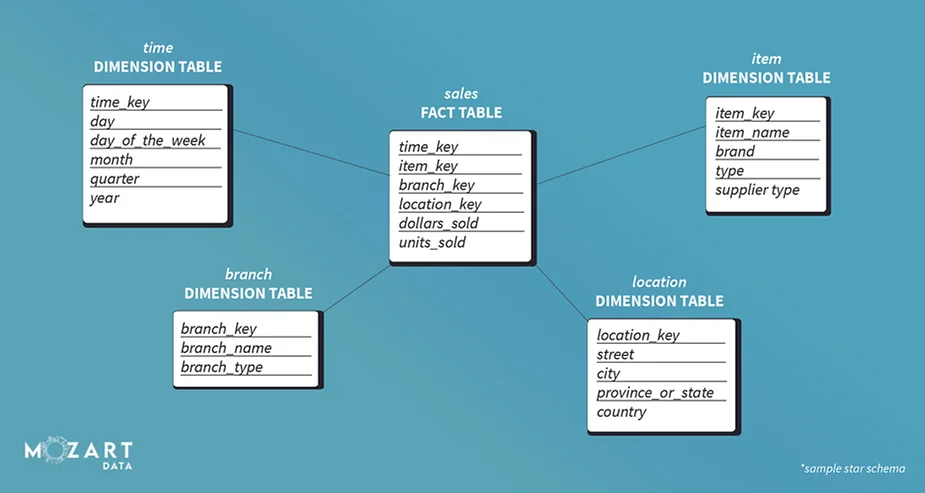
What Is a Fact Table?
In a dimensional model, a fact table is a primary table. It contains facts, measurements, and metrics of a business process. It also acts as a foreign key to dimensional tables. The data stored in a fact table is often numerical. You can find a fact table at the center of a snowflake schema or star schema. Fact tables help store report labels, don’t contain a hierarchy, and you can define it by its atomic level.
What Is a Dimensional Table?
A dimensional table stores information that provides dimensions of a fact and is joined by a foreign key to a fact table. Dimension tables include dimension attributes in the columns of a dimension table.
You can find dimension tables at the edges of a snowflake or star schema. They contain detailed data that is descriptive, complete, and quite wordy (and quality assured).
Dimension tables often take the form of descriptive characteristics of facts and are helped by their attributes. Dimensions sometimes contain one or more hierarchical relationships. There is also no set limit for the number of dimensions assigned to these relationships.
With Mozart Data, you can set up the whole data stack today and unleash your data team to unlock your full growth potential. Schedule a demo and see how we make access to data and analytics a breeze.


